Pyro vs NumPyro – VAE での速度比較
最近、VAE(変分オートエンコーダー)が個人的なブームです。去年ぐらいから、フリストンの自由エネルギー原理というものに興味を持ち始め、いろいろと勉強をし始めているのですが、そうした中で VAE に興味を持ち始めました。
自由エネルギー原理
ちなみに、自由エネルギー原理というのは「人間の脳が自由エネルギーを最小化するという形で様々な情報処理を行っていると考えると、脳の働きを統一的に理解できる」という仮説(原理?)のことで、いま脳科学者の間で非常に注目されているものです(間違っていたら、すみません…)。
こうした書籍を読むと、とりあえずなんだか凄そうだ…というのは、よく伝わってくるのですが、エンジニアの目線では「なんとなくわかるが、やっぱり実装してみないと、どうもわかった気がしない…」という訳で、VAE の実装を調べつつ、いろいろ勉強してみることにしました。
速度比較
VAE の実装としては、Reparameterization Trick という手法を使って実装するアプローチが一般的によく行われているのですが、今回はそうしたテクニックを使わずに実装を行っている Pyro と NumPyro で速度比較を行ってみています。
VAE の実装に関しては、Pyro でも NumPyro でも公式サイトにサンプルコードがありますので、今回はそれらのコードを参考にさせて頂きました。なお、これらのコードに興味がある方は下から参照して頂けたらと思います。


さて、今回このような形で2つの異なるプラットフォームで VAE のコードを走らせてみたのですが、その結果、次のようなことがわかりました。
1.NumPyro はやっぱり速かった
2.データの読み込み部分がボトルネックになりがち
1 については、Pyro の公式サイトにも「MCMC(HMC や NUTS)は、NumPyro の方が100倍速い…」とか書いてあるのですが

今回の実験の結果わかったのは「MCMC だけでなく、変分推論(SVI)の方も割と NumPyro が速かった…」ということです。
ただ、これはコードの書き方にも大きく依存している可能性もありそうで、単純に公式サイトにある例題を引っ張ってきただけでは、あまりフェアな比較にはならないかもしれない…という印象も持っています。
もっと具体的に言うならば、データの読み込み部分の実装の仕方で速度に大きな差が出ています。Pyro のサンプルコードはどちらかというとわかりやすさ重視で、データローダーなども PyTorch のものをそのまま使っているのですが、NumPyro の方はこの部分もかなり速度を意識した実装になっていて、その部分が高速化に大きく貢献していることがわかってきました。そこで、今回は次の3つのタイプのコードを走らせて、実行速度を比較をしてみました。
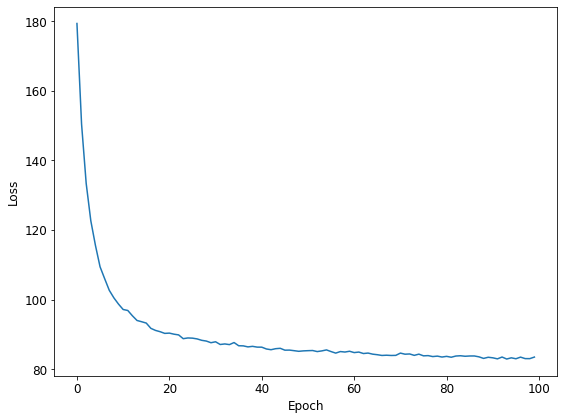
Pattern 1 : NumPyro の公式サイトのコードを少しだけ手直ししたもの
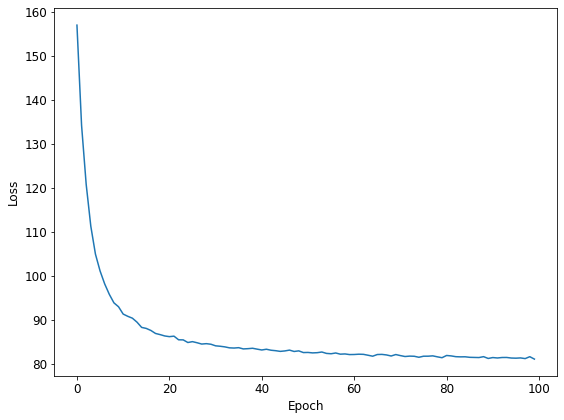
Pattern 2 : Pyro の公式サイトのコードを少しだけ手直ししたもの
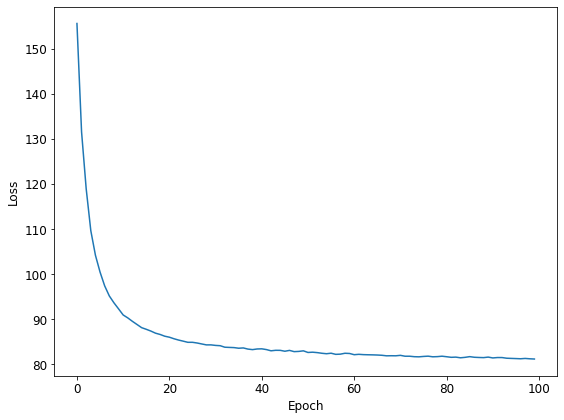
Pattern 3 : 2のコードのデータ読み込みの部分を高速化したもの
CPU のみの計算ではローカルマシンを使いましたが、GPU の計算では主に Google Colab (無料版)の GPU を使っています。
■ GPUなし: Local Machine (Intel Core i5-8400)
■ GPUあり: Google Colab (Tesla T4)
CPU での計算でローカルマシンを使ったのは、Google Colab の CPU が結構遅かったためで、私のマシンの CPU の方がより多くの人が使う CPU に近いスペックのでは…と思ったためです(GPU はそれほど多くの人が持っていないかもしれないので、Google Colab の方を使いました)。
時間を測ったのは推論に関する部分だけなのですが、概ね次のような感じになりました。なお、計測は大雑把に1回のみで測ったものなので、かなりラフな数値だと思って下さい。

単純に NumPyro と Pyro を比較してしまうと、NumPyro が恐ろしく速く見えるのですが、実はデータ読み込みの部分に少し手を入れるだけで、Pyro の方もかなり速くなりました。
ただ、NumPyro の場合は、データを全てメモリに読み込んでから、JAX & JIT による高速化の恩恵を受けられるような形でデータの読み込みをやっているので、この辺りは PyTorch をベースにしている Pyro ではなかなか難しいところもあるのかな…という気もしています。
また、Pattern 3 の Pyro の場合、実行時に GPU の負荷を見てみると、それほど負荷が上がっていないように見えるので、まだどこかに本質的ではないボトルネックがあるのではないか?…という気もしています。
こうした高速化の問題は、データのサイズやアルゴリズムの組み合わせで状況が変わるので、一概に 「NumPyro が速い」とか、「Pyro が遅い」とか言えない部分もあるのですが、今回試した感じでは変分推論(SVI)でも NumPyro が結構速かった…という印象を持っています。
なお、Pattern 1 の NumPyro の場合、実行時に GPU の負荷を見てみると、負荷がほとんど 100% に近いくらいになっていましたので、もっと強力な GPU を使うと、更に速くなる可能性はあるのではないかと思っています。
※ 今回の実験の後で VAE 以外のケースについて、自動生成した Guide による変分推論の速度を計測してみたのですが、GPU による高速化の効果はありませんでした(むしろ遅くなった!)。今回の実験の結果はあくまで VAE 限定で考えて頂いた方がよいかもしれません…
コードの詳細
今回時間の計測に使ったコードは下の方へまとめさせて頂きましたので、興味のある方はぜひご覧になって頂けたらと思います。
Pattern 1 / NumPyro :
Pattern 2 / Pyro :
Pattern 3 / Pyro :
NumPyro の方のコードは、公式サイトの方での解説が少ないので、少し多めに解説を入れました。また、Pyro の方は公式サイトに丁寧な解説があるので、解説はほとんど入れずにコードのみペタッと貼り付けています。
コードは比較をしやすいように変数名を揃えたり、いろいろいじっているので、もしかしたらどこかで変なことをしている可能性もあるのですが、もしおかしなことをしている部分がありましたら、知らせて頂けますと、ありがたいです。
補足: Pyro の更なる高速化
この記事を書いた後で、JIT を使うともう少し Pyro を速くできることに気づきました。基本的には Pattern 3 / Pyro の方で紹介しているコードの一部を次のように書き換えるだけです(損失を定義している箇所)。
修正前: loss=pyro.infer.Trace_ELBO()
修正後: loss=pyro.infer.JitTrace_ELBO()
Google Colab だと、CPU が遅いせいか、GPU を使ってもそれほど速くはならないのですが、CPU がそれなりに速いマシンですと、それなりに効果があるようです。当方の Local Machine (Intel Core i5-8400 + Geforce GTX1070) ですと、1min 22s くらいで走りました。ちなみに、コードの修正前は 1min 57s でした。
なお、PyTorch 自体にも、PyTorch JIT なるものがあるらしいので、そういったものと組み合わせると、更に速くなったりするかもしれないのですが、今回は試してみていません。