Variational Autoencoder の実装 – Pyro
概要
前回の記事では NumPyro による Variational Autoencoder (VAE) の実装例を紹介させて頂きましたが、今回は Pyro で VAE の実装例をご紹介させて頂こうと思います。前回と同じく、基本的には今回も以下の公式サイトにあるコードを利用させて頂いているのですが、NumPyro版のコードとの比較しやすくするために、少しだけコードを NumPyro版のコードに書き方を寄せています。

Pyro と NumPyro という違いはあるものの、変数名や関数名などはなるべく似せるようにしたので、前回の記事を読んで頂いた方には、比較的簡単にコードの方を理解して頂けるようになっているのではないかと思っています。前回の記事はこちらです。
前回の記事ではコードに適宜解説を入れていたのですが、基本的なコードの流れは前回と一緒なので、今回はあまり解説を入れずに、コードを貼り付けるだけにしました(その方が見やすいかと思いました…)。
Install Packages
!pip install pyro-pplImport Packages
import time
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils as utils
from torchvision import datasets, transforms
import pyro
import pyro.distributions as dist実行環境をセットします。GPU での高速化を試したいときには、下の 'cpu’ の部分を 'cuda’ に置き換えて下さい。
device = 'cpu' # define 'cuda' for GPU
torch.device(device)plt.rcParams['font.size'] = 12
plt.rcParams['figure.figsize'] = [8, 6]Define Parameters
DATA_DIR = '/mnt/extra/data/mnist/MNIST/raw'
Z_DIM = 50
HIDDEN_DIM = 400
OUT_DIM = 28 * 28
NUM_EPOCHS = 100
BATCH_SIZE = 256
LEARNING_RATE = 1.0e-3
NUM_WORKERS = 2PIN_MEMORY = True if 'cuda' in device else FalseDefine Dataset
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Lambda(lambda x: (x > 0.5).to(torch.float32)),
transforms.Lambda(lambda x: x.view(-1))
])
dataset_train = datasets.MNIST(DATA_DIR, train=True, download=True, transform=transform)
dataset_valid = datasets.MNIST(DATA_DIR, train=False, download=True, transform=transform)
dataloader_train = utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=False, num_workers=NUM_WORKERS, pin_memory=PIN_MEMORY)
dataloader_valid = utils.data.DataLoader(dataset_valid, batch_size=BATCH_SIZE, shuffle=False, num_workers=NUM_WORKERS, pin_memory=PIN_MEMORY)Define VAE
class Decoder(nn.Module):
def __init__(self, z_dim, hidden_dim, out_dim):
super().__init__()
self.fc_dec1 = nn.Linear(z_dim, hidden_dim)
self.fc_dec2 = nn.Linear(hidden_dim, out_dim)
def forward(self, z):
x = self.fc_dec1(z)
x = F.softplus(x)
x = self.fc_dec2(x)
x = torch.sigmoid(x)
return xclass Encoder(nn.Module):
def __init__(self, z_dim, hidden_dim, out_dim):
super().__init__()
self.fc_enc = nn.Linear(out_dim, hidden_dim)
self.fc_loc = nn.Linear(hidden_dim, z_dim)
self.fc_log_std = nn.Linear(hidden_dim, z_dim)
def forward(self, x):
x = self.fc_enc(x)
x = F.softplus(x)
z_loc = self.fc_loc(x)
z_std = torch.exp(self.fc_log_std(x))
return z_loc, z_std下のコードのポイントは、pyro.module という関数で、これが Encoder / Decoder のニューラルネットのパラメータを変分推論の際に最適化の対象として登録する処理をしています。NumPyro の場合は、haiku_module という関数が同じ役割を果たしていました。
class VAE(nn.Module):
def __init__(self, z_dim, hidden_dim, out_dim):
super().__init__()
self.encoder = Encoder(z_dim, hidden_dim, out_dim)
self.decoder = Decoder(z_dim, hidden_dim, out_dim)
self.z_dim = z_dim
def model(self, batch):
batch_dim = batch.shape[0]
pyro.module('decoder', self.decoder)
with pyro.plate('batch', batch_dim):
z_loc = batch.new_zeros((batch_dim, self.z_dim))
z_std = batch.new_ones((batch_dim, self.z_dim))
z = pyro.sample('z', dist.Normal(z_loc, z_std).to_event(1))
loc_img = self.decoder(z)
pyro.sample('obs', dist.Bernoulli(loc_img).to_event(1), obs=batch)
def guide(self, batch):
batch_dim = batch.shape[0]
pyro.module('encoder', self.encoder)
with pyro.plate('batch', batch_dim):
z_loc, z_std = self.encoder(batch)
pyro.sample('z', dist.Normal(z_loc, z_std).to_event(1))Inference
def train(svi, dataloader, device):
loss_sum = 0.
for x, _ in dataloader:
x = x.to(device)
loss_sum += svi.step(x)
num_data = len(dataloader.dataset)
loss_ave = loss_sum / num_data
return loss_avedef evaluate(svi, dataloader, device):
loss_sum = 0.
for x, _ in dataloader:
x = x.to(device)
loss_sum += svi.evaluate_loss(x)
num_data = len(dataloader.dataset)
loss_ave = loss_sum / num_data
return loss_avepyro.clear_param_store()
vae = VAE(Z_DIM, HIDDEN_DIM, OUT_DIM).to(device)
optimizer = pyro.optim.Adam({'lr': LEARNING_RATE})
svi = pyro.infer.SVI(vae.model, vae.guide, optimizer, loss=pyro.infer.Trace_ELBO())%%time
losses = np.zeros(NUM_EPOCHS)
for k in range(NUM_EPOCHS):
t_start = time.time()
_ = train(svi, dataloader_train, device)
losses[k] = evaluate(svi, dataloader_valid, device)
t_end = time.time()
print('Epoch {}: loss = {:.2f} ({:.3f} s)'.format(k, losses[k], t_end - t_start))Epoch 0: loss = 157.04 (9.351 s)
Epoch 1: loss = 134.26 (9.611 s)
Epoch 2: loss = 120.80 (8.103 s)
Epoch 3: loss = 111.29 (8.848 s)
## 中略
Epoch 97: loss = 81.17 (8.379 s)
Epoch 98: loss = 81.61 (9.127 s)
Epoch 99: loss = 81.06 (8.983 s)
CPU times: user 43min 45s, sys: 23min 48s, total: 1h 7min 33s
Wall time: 14min 4splt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.tight_layout()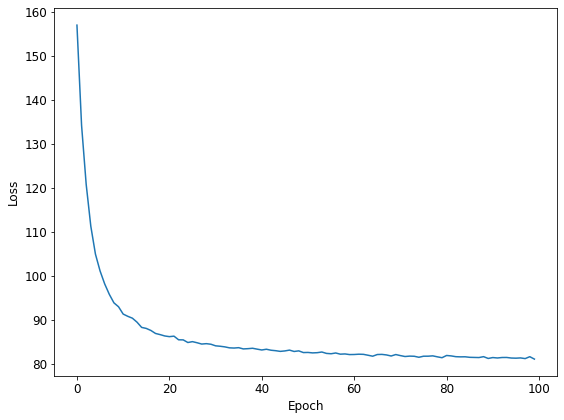
Check Results
最初のバッチの先頭の5枚の画像について、VAE が入力された画像を復元できているかチェックします。なお、最初の投稿では下のコードが間違っておりました。お詫びして訂正させて頂きます。
batch_image = next(iter(dataloader_train))[0]z_loc, z_std = vae.encoder(batch_image.to(device))
z = dist.Normal(z_loc, z_std).sample()
batch_recon = vae.decoder(z).cpu().detach().numpy()fig, axes = plt.subplots(2, 5, figsize=(10, 3))
for k in range(5):
axes[0][k].imshow(batch_image[k].reshape(28, 28), 'gray')
axes[0][k].set_xticks([])
axes[0][k].set_yticks([])
axes[1][k].imshow(batch_recon[k].reshape(28, 28), 'gray')
axes[1][k].set_xticks([])
axes[1][k].set_yticks([])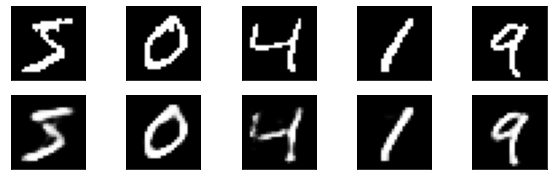
Summary
最後に、推論にかかった時間を記しておきます。計測しているのは、%%time で時間を測っているセルのところです。Google Colab と Local Machine の2通りで時間を測っています。Google Colab 上では「GPUあり」の場合の実行時間を計測し、Local Machine では「GPUなし」の場合の実行時間を計測しました。
GPUなし / Local Machine (Intel Core i5-8400) : 14min 4s
GPUあり / Google Colab (Tesla T4) : 13min 20s
今回、更に Local Machine でも「GPUあり」で計測してみると、次のような結果が得られました。
GPUあり / Local Machine (Intel Core i5-8400 + Geforce GTX1070) : 5min 52s
Pyro のコードを実行したときには、CPU もかなり負荷が高くなっていましたので、Google Colab の場合に GPUを使っても Google Colab で実行速度が速くならなかったのは Colab の CPU(無料版)が遅かったせいかもしれません。GPU の性能に関しては、Tesla T4 と Geforce GTX1070 の間で大きな性能差はなかったような気がします。
ちなみに、前回 NumPyro で VAE のコードを実行させたときの結果は、次の通りです。
GPUなし / Local Machine (Intel Core i5-8400) : 2min 34s
GPUあり / Google Colab (Tesla T4) : 0min 18s
JAX 恐るべし…という感じですが、NumPyro版のコードは、予め全ての画像データを全てメモリにロードするようなことをしていたので、普通にファイルからデータを読み込む Pyro 側の方がかなり不利な条件であったことは想定できます。次回はこの辺りもある程度条件を近づけて、実行時間を計測してみたいと思います。
※ なお、実行時間については、あまり正確には測っていませんので、あくまで参考程度に留めておいて頂けましたら幸いです。
お願い
記事につきましては、間違いないように十分に気をつけて書いたつもりなのですが、どこかで変なことを行っているかもしれません。お気付きの点がありましたら、ご面倒でもお問合せの方からご指摘頂けますと、ありがたいです。