NumPyro による微分方程式のパラメータ推定 – 化学反応
概要
前回ご紹介したバネマス系のモデルに引き続いて、今回は化学反応の速度に関連するパラメータをデータから推定する、ということをやってみたいと思います。
化学反応の速度を考える際に出てくる「反応速度式」に出てくる速度定数や次数をデータから推定したいという訳です。私は化学の専門家でも何でもないので、今回はこちらの資料を参考にコードを書いてみました。
http://www.chem.konan-u.ac.jp/PCSI/web_material/Pchem/Web/Web_page168_203_suppl.pdf
こちらの資料に中に一酸化窒素と酸素の反応を書いた次のような化学反応の式があるのですが
$$ 2NO + O_2 \rightarrow 2NO_2 $$
こちらの化学反応をなんとなくイメージしています。上の反応が進んでいくと、左辺の一酸化窒素の濃度と酸素の濃度はどんどん減ってゆき、右辺の二酸化窒素の濃度が増えてゆきます。この反応のプロセスを式で表現すると、次のような式になります。
$$ \begin{align} \frac{d[NO]}{dt} = -2 v(t),\; \frac{d[O_2]}{dt} = – v(t),\; \frac{d[NO_2]}{dt} = 2 v(t) \end{align} $$
$v(t)$ は反応速度式と呼ばれるもので、上の化学反応の起こる速度を表しています。この反応速度式はいまの場合は、次のようになることが知られていますので
$$ v(t) = k[NO]^2[O_2] $$
この式を上の式に代入してやると、我々の見慣れた形式の微分方程式が出てきます。
しかし、上でご紹介した資料によれば一般的には反応速度式はこうした形になるとは限らないそうです。つまり、いまの場合では反応速度式が例えば次のような形で表されるとしても
$$ v(t) = k[NO]^m[O_2]^n $$
必ずしも m=2, n=1 とはならず、m, n は本来は実験により決定する量なのだそうです。
これらのパラメータには、それぞれ名前が付いており、k は速度定数、m や n は次数と呼ばれるそうですが、これらのパラメータをデータから求める、というのが今回のお題になります。
Install Packages
まずは、NumPyro をインストールします。Google Colab なら下のコマンドでうまく行くはずですが、自前の環境でされている方は環境を壊さないようにご注意下さい。また、Google Colab をお使いの方はランタイムの再起動をお忘れなく!
!pip install --upgrade jax==0.2.17 jaxlib==0.1.71+cuda111 -f https://storage.googleapis.com/jax-releases/jax_releases.html
!pip install numpyro==0.7.2
!pip install arviz==0.11.2
!pip install japanize_matplotlib
Import Packages
必要なパッケージをインポートします。
import jax
import jax.numpy as jnp
import jax.experimental.ode as ode
import numpyro
import numpyro.distributions as dist
import arviz as az
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
import japanize_matplotlib
plt.rcParams['font.size'] = 14
実行環境として cpu を選択します。gpu とかも選べますが、速くはならないことが多いような気がします…
numpyro.set_platform('cpu')
numpyro.set_host_device_count(4)
Generate Data
微分方程式を解いて、まずは実験データを捏造します。頭の中では、下の反応をイメージしていますが
$$ 2NO + O_2 \rightarrow 2NO_2 $$
ここでは、少し単純化して、物質 A と物質 B が反応して、物質 C が生成されるとします。
$$ 2 A + B \rightarrow 2 C $$
なお、反応速度式は、次のような形になっているものとします。
$$ v(t) = k[A]^{m}[B]^{n} $$
こうした仮定のもとで、微分方程式を書いてみると、次のようになります。
def dz_dt(z, t, k, m, n):
A = z[0]
B = z[1]
C = z[2]
V = k * jnp.power(A, m) * jnp.power(B, n) # 反応速度
dA_dt = -2.0 * V
dB_dt = -V
dC_dt = 2.0 * V
return jnp.stack([dA_dt, dB_dt, dC_dt])
この微分方程式を解いてみると、次のようになります。
m_true = 2.0 # 次数(A)
n_true = 1.0 # 次数(B)
k_true = 0.2 # 速度定数
t_true = jnp.arange(0, 20).astype(float)
z_init = jnp.array([1.4, 1.0, 0.1]).astype(float) # 濃度の初期値
z_true = ode.odeint(dz_dt, z_init, t_true, k_true, m_true, n_true)
plt.plot(z_true, label=['A', 'B', 'C'])
plt.xlabel('時間')
plt.ylabel('濃度')
plt.legend(loc='upper right');
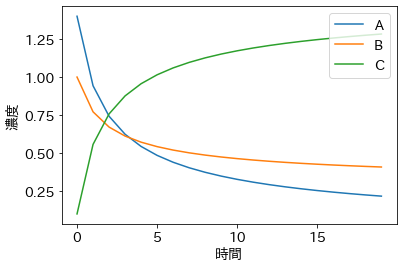
なお、物質の濃度の初期値は適当に決めました。
次に、この微分方程式の解に雑音を加えます。雑音としては、対数正規分布を使います。こうした場合に、雑音として対数正規分布を使うのが正しいかはわからないのですが、とりあえず対数正規分布でやってしまっています。
測定器に起因する雑音だと、実際に雑音がどのようになるかわからないのですが、実験室の温度や窓から入った日光などの環境のパラメータが化学反応のプロセスに影響を与えるとすると、そうしたタイプの雑音は +0.1%, -0.2%, -0.4%, … みたいな比率で、物質の濃度に影響を与える可能性が高いと考えて、今回対数正規分布を選択しました。
t_observed = t_true
z_observed = np.random.lognormal(mean=jnp.log(z_true), sigma=0.05)
plt.plot(z_observed, 'o')
plt.plot(z_true, '--', color='gray')
plt.xlabel('時間')
plt.ylabel('濃度');
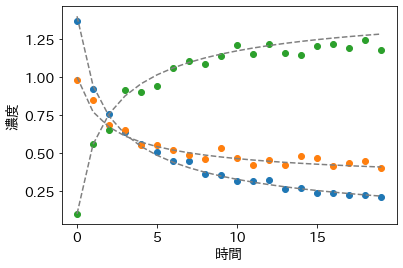
いずれにしても、以上のようにして測定データを捏造することができました。
Define Model & Inference
次に、この測定データから微分方程式のパラメータを推定していきます。
def model(t, z_observed=None):
# 反応速度式の次数に関する事前分布
m = numpyro.sample('m', dist.HalfNormal(10))
n = numpyro.sample('n', dist.HalfNormal(10))
# 物質の濃度に関する事前分布
A_init = numpyro.sample('A_init', dist.HalfNormal(10))
B_init = numpyro.sample('B_init', dist.HalfNormal(10))
C_init = numpyro.sample('C_init', dist.HalfNormal(10))
z_init = jnp.stack([A_init, B_init, C_init])
# 速度定数に関する事前分布
k = numpyro.sample('k', dist.HalfNormal(10))
# 微分方程式のソルバー
z_mean = ode.odeint(dz_dt, z_init, t, k, m, n)
# 観測プロセスのモデル(対数正規分布)
sigma = numpyro.sample('sigma', dist.HalfNormal(10))
numpyro.sample('y', dist.LogNormal(jnp.log(z_mean), sigma), obs=z_observed)
%%time
nuts = numpyro.infer.NUTS(model, target_accept_prob=0.99)
mcmc = numpyro.infer.MCMC(nuts, num_warmup=2000, num_samples=1000, num_chains=4, progress_bar=False)
mcmc.run(jax.random.PRNGKey(0), t_observed, z_observed=z_observed)
mcmc_samples = mcmc.get_samples()
idata = az.from_numpyro(mcmc)
CPU times: user 10min 51s, sys: 259 ms, total: 10min 51s
Wall time: 3min 10saz.plot_trace(idata);
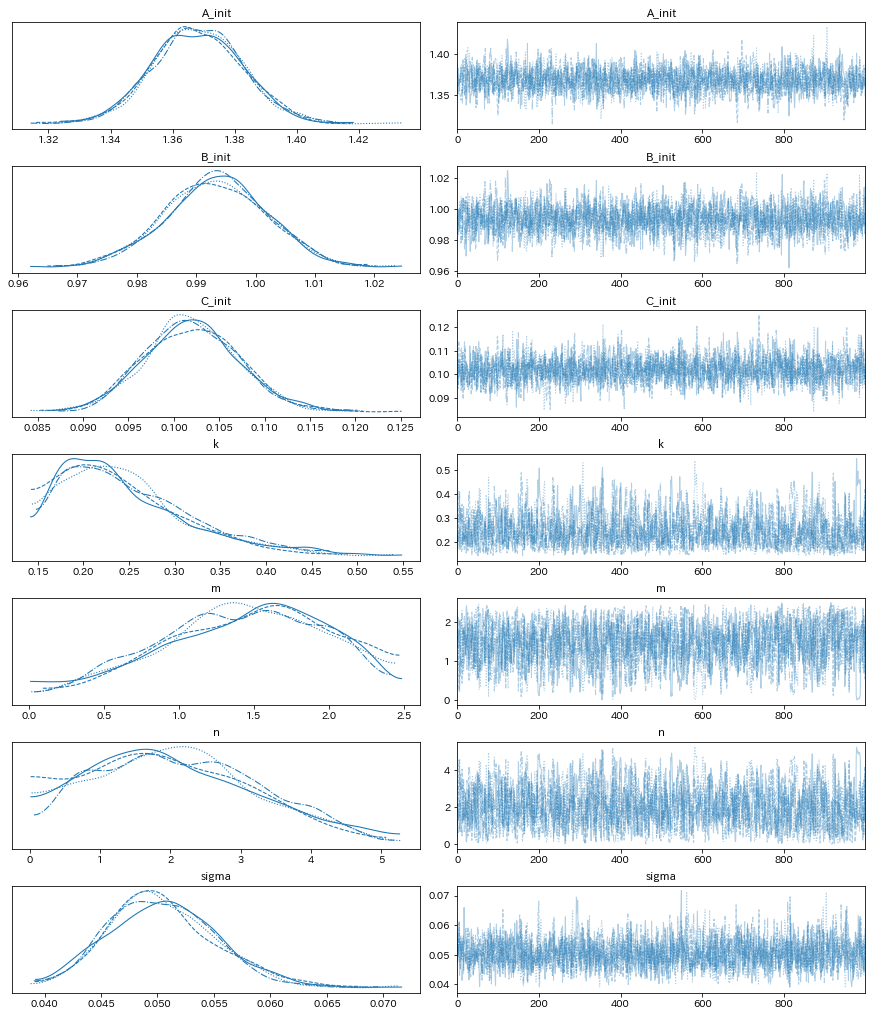
az.summary(idata)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| A_init | 1.368 | 0.014 | 1.343 | 1.396 | 0.000 | 0.000 | 1652.0 | 2032.0 | 1.0 |
| B_init | 0.993 | 0.009 | 0.977 | 1.010 | 0.000 | 0.000 | 1882.0 | 2191.0 | 1.0 |
| C_init | 0.102 | 0.005 | 0.093 | 0.112 | 0.000 | 0.000 | 2148.0 | 2448.0 | 1.0 |
| k | 0.247 | 0.069 | 0.143 | 0.375 | 0.002 | 0.002 | 1108.0 | 1181.0 | 1.0 |
| m | 1.429 | 0.544 | 0.495 | 2.411 | 0.016 | 0.012 | 1094.0 | 1124.0 | 1.0 |
| n | 2.065 | 1.149 | 0.079 | 4.093 | 0.035 | 0.026 | 1079.0 | 1163.0 | 1.0 |
| sigma | 0.050 | 0.005 | 0.042 | 0.059 | 0.000 | 0.000 | 2245.0 | 2215.0 | 1.0 |
Summary
残念ながら、反応速度式のパラメータはあまりうまく推定することができませんでした。一応、m=2, n=1 のあたりにピークはあるのですが、分布がかなり広がってしまっています。
もしかしたら、1回だけの実験ではなく、複数回の実験結果を融合することができれば、もうちょっとシャープな分布になるかもしれません…