データサイエンスのオフロード
これは極めて個人的な見解なのですけど、データサイエンスにも「オフロード」と「オンロード」のような区別があるのではないかと思っています。
つまり、データを「道」、学習器を「自動車」と考えたときに、いつも同じように舗装された道を走る場合と、必ずしも舗装されているとは限らない道を走る場合には、大きな違いがあるのではないか?ということです。
次にカーブを曲がった先で、どんな道が出てくるかわからないようなコースを走る場合と、ひたすらサーキットを全力で周回する場合では、必要な自動車が大きく変わってくるのではないか?みたいなことです。
もちろん、ラリーカーがサーキットを走ることもできるでしょうし、サーキットカーが公道を走ることもできるかもしれませんが、本来の性能を十分に出し切ることはなかなか難しいのではないでしょうか。
データサイエンスのオンロード
オンロードの場合では、自動車が走るのは基本的には舗装された道路です。舗装されている、とは言っても、またサーキットと一般公道では違うかもしれませんが、まあまあ同じようなものだとしておきます。
特に、サーキットの場合は基本的に同じコースを周回します。つまり、このような場合では、学習器は学習時に使ったデータと同じようなデータにしか遭遇しません。
工場や実験室のようなある程度環境が固定された状況でデータを取り、学習器に学習をさせて、新しいデータに対する予測などを行う、といった状況です。こういった状況では、未来に出現するデータは基本的に過去に遭遇したデータと同じような分布を持っていますから、安心していつも通りの手順で、学習器を考えてゆくことができます。
このプロセスの前提になっているのは、過去に遭遇したものと同じようなデータにしか遭遇しない、という点です。この前提が保たれている限りは、学習器の性能は未来においても保証されます。
パラメータをどんどんチューニングして、性能を突き詰めていったり、変数同士の因果関係を調べたり…といったことも比較的やりやすい状況ではないかと思います。
逆に、このような前提が成り立たないものも存在します。これが私の考えている「データサイエンスのオフロード」という状況です。
データサイエンスのオフロード
現実世界においては、未来に遭遇するデータが過去に遭遇したデータと大きく乖離するケースというのが、ままあります。
これは、例えば店舗の売上データのようなものです。こうしたデータでは未来で遭遇するデータが必ずしも過去に遭遇したデータとは同じ傾向を持つとは限りません。過去のデータで学習させた学習器が未来のデータに対してもうまく機能する保証がありません。
なぜならば、世界が閉じていないからです。
工場や実験室などの閉じた世界であれば、ある程度まで環境要因を固定化することが可能なので、未来のデータが過去のデータと同じような動きをすることが想定できますが、店舗の売り上げデータのようなものは外界から常に影響を受け続けます。
そうした外界からの影響が本当に小さなゴミのようなものであればよいのですが、もっと大きな「観測不能なファクター」があった場合には、あまり良い予測ができなくなります。
観測不能なファクター
観測不能なファクターがある場合というのは、具体的にはどういった場合でしょうか?例えば、下のような単純な X と Y のデータを考えてみます。

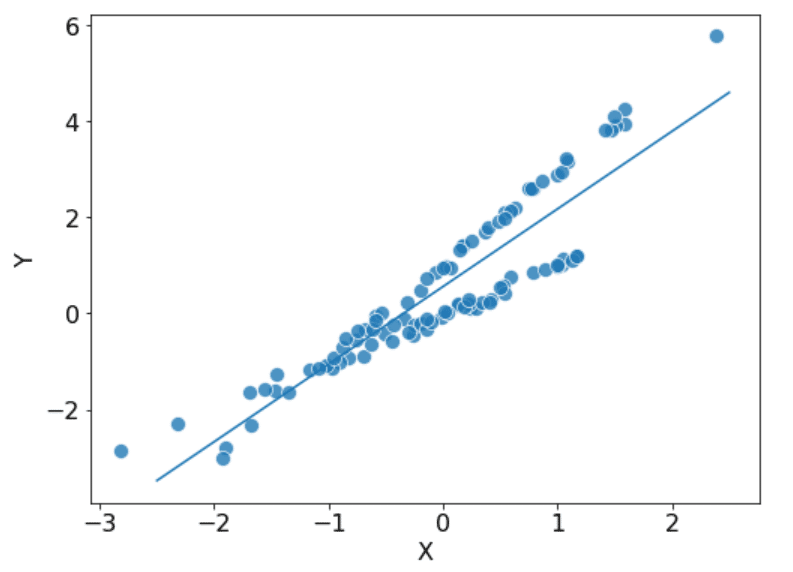
このデータはプロットすると、次のような形になるのですが、どうでしょうか。
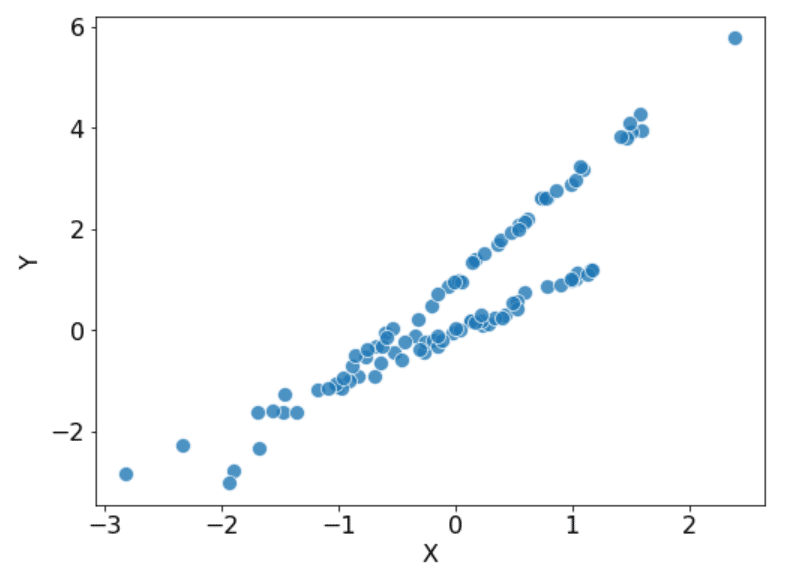
うまくモデル化できるでしょうか?とりあえず線形回帰でやってみると、こんな感じです。
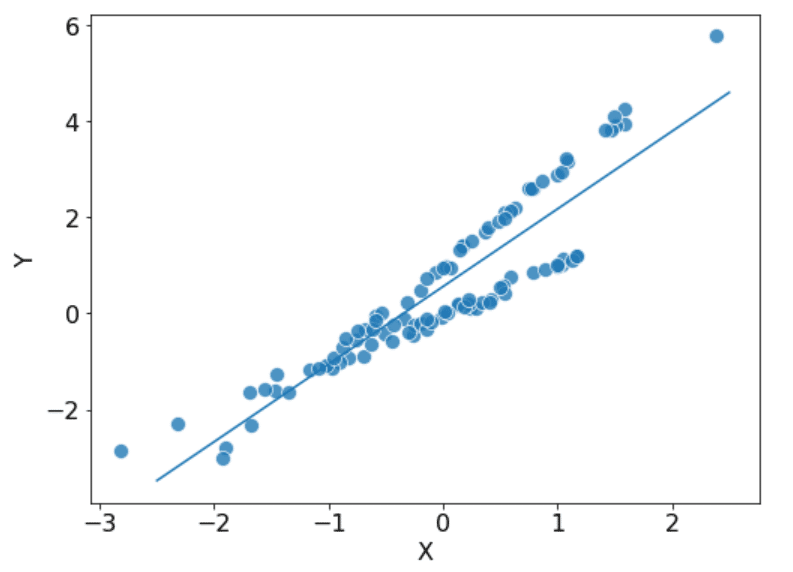
あんまりよくないかもしれません… 実はこのデータの背後には、観測されていないファクター C が存在しており、本当のテーブルは次のような形になっています。
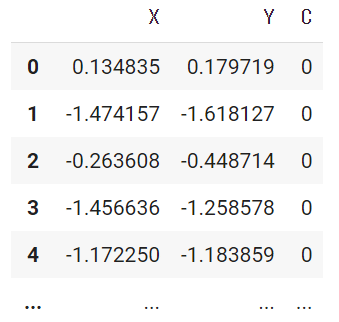
このファクター C は0か1の値を取るのですが、この値に依存してデータを生成するモデルが切り替わるような仕組みになっています。実際にデータを生成しているモデル自身は実は単純な線形モデルです。
ポイントは、このファクター C が観測できるかどうかです。このファクターがどこかのデータベース上に存在する変数であれば、それを取ってくればよい訳ですが、そうでないとしたらどうでしょうか?
例えば、人間の頭の中にしかない情報や人間の遺伝子のようなものだったら、どうでしょうか?…そう簡単には観測できないような気がします。少なくとも結構コストはかかりそうです。
観測不能なファクターをどうするか?
では、こうした観測不能な(あるいは観測の難しい)ファクターがあった場合はどうすればよいでしょうか?
一番簡単なのは「なかったことにしてしまう」ことです。まあ、観測できないものはあれこれ考えてもしょうがない訳なので、ある意味でリーズナブルな考え方とも言えます。
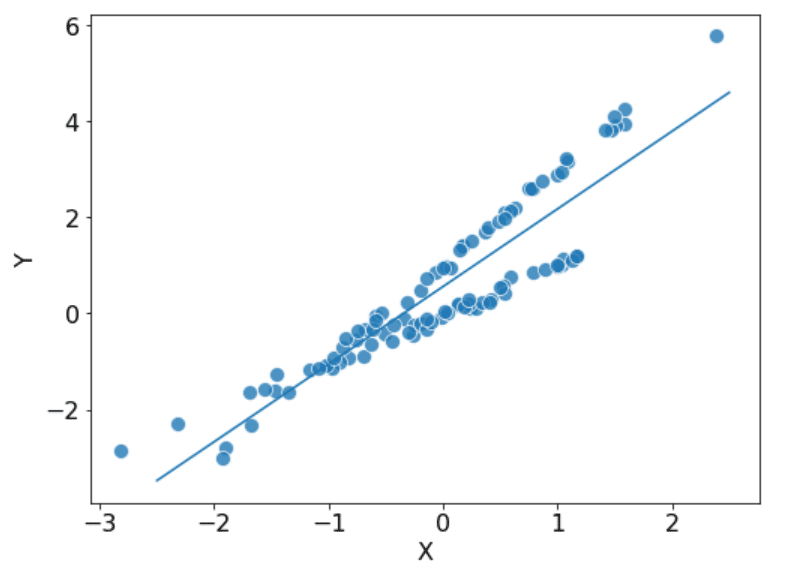
しかし、こんな風に明らかに2つのモデルが混じり合っているように見えるのに、そうした事実を無視して先に進んでしまうのはちょっと気が引けます。できれば、こんな感じにしたいところです。
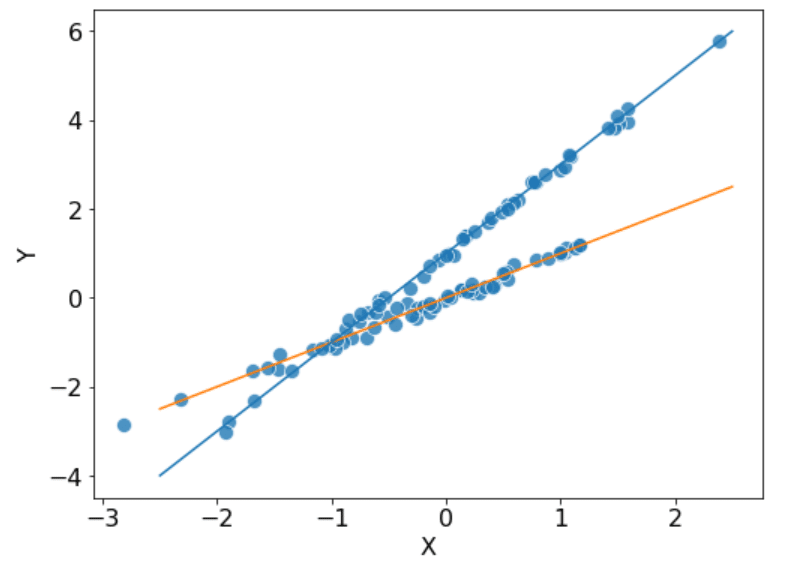
で、こんなことができるかというと、実はできます。R だと flexmix というパッケージを使うと簡単にできてしまうようです。

そして、このモデルのポイントは、見えないものを単純に無視してしまうのではなく、見えないものは見えないものとして積極的に「潜在変数」としてモデルに取り込んでいる…という点です。
で、こんなの前に見たことがあるな…と思った人がいるかもしれませんが、その人は鋭いです!クラスタリングです。
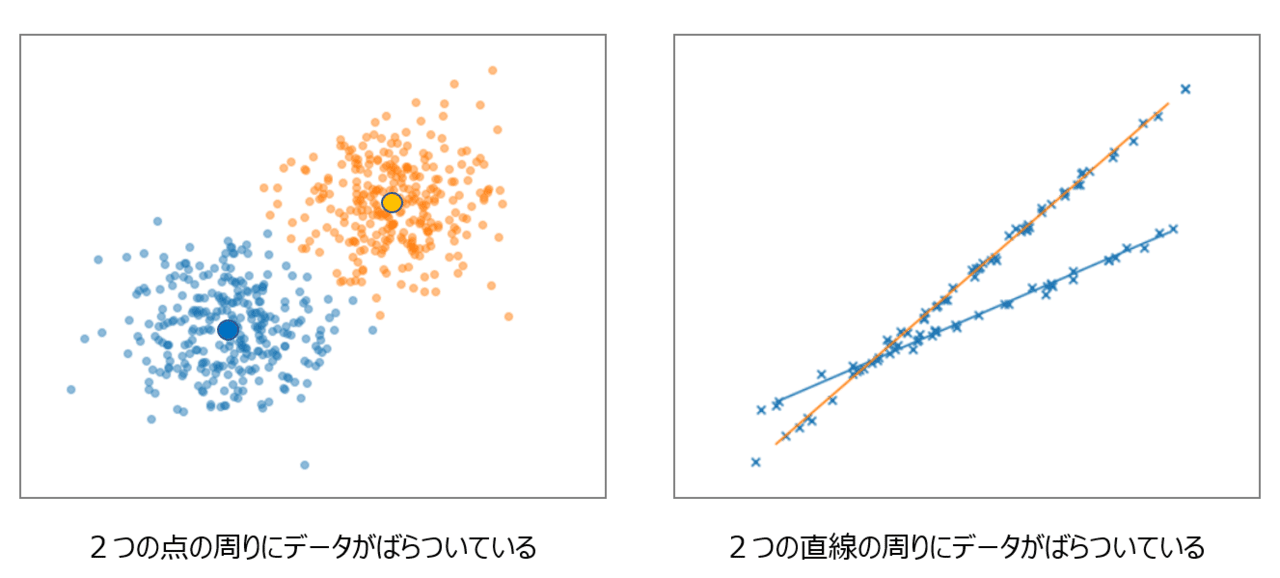
クラスタリングも、そのモデルの中には「潜在変数」が組み込まれており、データがどちらのグループから出たのかというラベルがわからない状態から、データをグループ分けしてゆきます。クラスタリングの場合は「中心」になっているのは「点」なのですが、Mixture of Regressions の場合は「中心」になるのは「回帰モデル」になっています。
潜在変数を含むモデル
以上のように、モデル化の対象に観測できない変数が潜んでいたとしても、うまくモデルに「潜在変数」として取り込むことができれば、ある程度なんとかなることはわかってきました。
しかし、実際のところ、こうした「潜在変数」を含むモデルにはたくさんの悩みがあります。全てを網羅できている訳ではないと思いますが、幾つか挙げるとこんな感じではないかと思います。
■ 潜在変数の推定自体が難しいことがある
■ 潜在変数の推定のための計算コストが高いことが多い
■ 潜在変数をどのように組み込むか人間が考える必要がある
…
こうした問題を回避するために賢い人たちがさまざまな知恵をひねり出してくれてはいるのですが、基本的にはこうした訳わからんものを組み込んでいくと、モデルは段々と扱いの難しいものへ変わってゆきます。
つまり、「潜在変数を含むモデル」は一見スマートな方法に見えていた訳ですが、そこにはそれなりの弱点があり、場合によっては「コマけぇことは気に気にするな!」と先に進んでしまうことも実用上は優れた考え方であることもある…ということは言えるのではないかと思っています。
ただ、ポイントになるのはこうした状況でも「最高性能を目指すことに意味があるのか?」ということです。
モデルに非線形性を導入したりすれば、もしかしたらちょっと精度を上げることができるかもしれませんが、果たしてそれに意味があるのか?よくよく考えてみる必要があるのではないかと思っています。
変数はそこにあるのか!?
ここ数年、世界はコロナという未曽有の事態を経験してきました。おそらく、多くの人たちはこうした感染症が国をまたいで広がり、世界規模の打撃を与えることを予見できなかったはずです。
では、もし先ほどのファクター C というフラグが「コロナ前」と「コロナ後」を指し示すフラグだったらどうでしょうか?
おそらく、我々はコロナを経験する前には、こうしたフラグの存在すら意識できていなかったはずです。そして、我々の手元にも「コロナ前」のデータしか存在しなかったはずです。
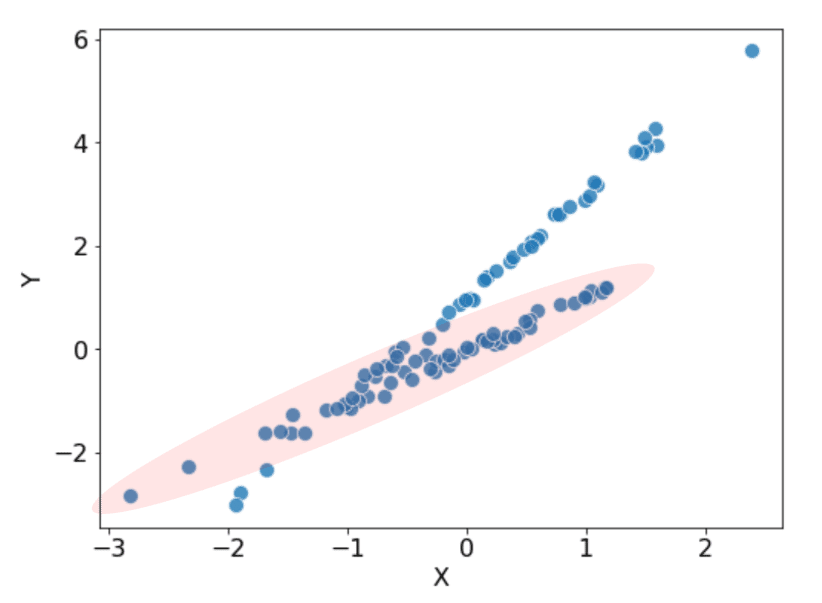
例えば、先ほどのデータで薄赤で塗られた部分が「コロナ前」のデータで、我々の手元にあるデータがこのデータだったとすると、このデータで学習させたモデルはそのままでは「コロナ後」には使えないことになります。
一般的に、こうした問題はデータサイエンティストたちには「共変量シフト」として意識されている問題ではないかと思うのですが、ポイントはそもそもコロナ前にはこのフラグが「その存在を意識すらされていなかった」という点です。
コロナ後であれば、これは我々が認識することができる規模の歴史的な事象ですから、人間が少しだけ手助けしてやることで、モデルの性能を保つことができるだろうとは思いますが、こんな大規模な事象でなければ、なかなか気づくことすらできなかった可能性もあります。
例えば、「ポケモン GO が流行っているかどうか」というファクターが自分のモデルの予測性能を上げてくれる可能性があったとしても、そもそもその変数の認識すらされないこともあり得る訳なのです。
要するに、世界には次のようなややこしいものが満ち溢れているということが言えるかと思います。
■ 存在を意識すらされていない変数
■ 観測不能な変数
■ 観測の難しい変数
■ 観測にコストがかかる変数
…
工場や実験室のように、閉じた世界の中でこうした変数の影響を可能な限り排除できる環境ならば、こうしたことに頭を悩ませなくてよいかもしれないですが、世の中のデータはそういった環境で生み出されるデータばかりではありません。
場合によっては、こうしたものが満ち溢れたジャングルみたいな場所を全力疾走するオフロードみたいな世界もある…ということなのです。
結論は…
で、何が言いたいのかと言えば、月並みかもしれませんが「データ解析と一言で言ってもその対象になるデータはさまざまだ」ということです。
F1のように、ある程度環境の固定された場所を全力で走るようなことが想定されている世界でのデータ解析もあれば、ラリーのように未知の要素をたくさん含んだ世界を全力疾走しなければならないような世界でのデータ解析もあります。
ポイントは、そうした背景や文脈をごちゃ混ぜにして議論をしないことです。これをごちゃ混ぜにしてしまうと、F1の話をラリーの世界に持ち込んだり、逆に、ラリーの世界の話をF1の世界に持ち込んだりすることになってしまい、訳のわからないことになってしまいます。
とにかく、「最高の精度を目指せばいい…」というのがいつでも正解であるとは限りませんし、「線形のモデルくらいで十分だ」というのも常に正解ではないだろうという訳です。
オマケ:紅の豚
私の好きな映画に宮崎駿の「紅の豚」という映画があるのですが、その中でこんなシーンが出てきます(これだけだと、どういうシーンか全くわからないかもしれませんが…)。
子供:いつものだけでいいんですか?高性能焼夷弾とか徹甲弾も入荷してますよ
ポルコ:坊主、俺たちゃ戦争やってるんじゃねえんだよ
↑ 目的を見失って、大掛かりな道具を入れ込もうとしてしまう罠
ピッコロ:出どころは聞くな。1927年のシュナイダー・カップでこいつをつけたイタリア艇はカーチスに負けたんだ。だがこいつのせいじゃないメカニックがヘボだったからだ。フフフ…血が騒ぐなぁ。
ポルコ:あんまりデリケートにチューンするなよ。レースじゃねえんだからな。
↑ どういう状況になるか予見できない状況でチューンし過ぎる罠
ポルコの場合は、こうした誰もが陥りそうな罠を絶妙に避けつつ、最後は青あざだらけになりながら「なぁに、軽いもんよ…」と言ってのける訳です。カッコいいですね ^^