Google 版 COVID-19 のモデルの概観
概要
最近、Google版の COVID-19 のモデルを見ていて、いろいろインスパイアされる部分があったので、紹介してみたいと思います。
ただ、私自身は疫学の専門家でもないので、本来はこのモデルを解説できるような立場にはいないと思うのですが、モデルの構築の仕方とか、考え方がこれからのモデリングの方向性のひとつを示唆しているように思えたので、私のわかる範囲でいろいろと解説を加えてみたいと思います。
なお、具体的なモデルの詳細については、下のURLにあるホワイトペーパーがあるので、詳しい方はそちらを直接読んだ方が早いかもしれないです。
https://storage.googleapis.com/covid-external/COVID-19ForecastWhitePaper.pdf
モデル
Google から発表されたこのモデルでは SIR とか SEIR と呼ばれる区画モデル(Compartment Model)をベースにモデルを構築しています。

例えば、SIR と呼ばれるモデルは、基本的には次のような常微分方程式のモデルなのですが、Google はこうしたモデルをベースに、機械学習で拡張するというアプローチを取っています。
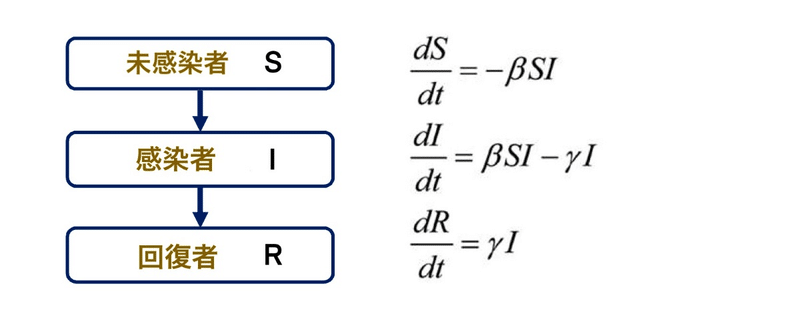
上の方程式もパッと見るとよくわからないのですが、基本的には「新規の感染者数が、未感染者と感染者の数の両方に比例して増える」という関係性を微分方程式で表現したものになっています。
一般的に、データサイエンスの分野で解釈性の高いモデルと言うと、線形回帰モデルや一般化線形回帰モデルなどを思い浮かべることが多いかと思うのですが、もしかしたら常微分方程式もその範疇に加えてよいのかもしれないということを、今回の Google のモデルを見ていて気づかされました。
特に、「データによる未来予測」を考えた場合に、過去のデータが十分に存在していて、なおかつ予測したい未来が過去のパターンから大きく逸脱しないような場合では、「データを学習させて、次に予測させる」といういつもの手順だけでそれなりの予測ができるはずですが、今回のような過去に経験のないような状況では、そもそも過去のデータがありませんので、いつもの手順だけではあまりよいモデルを構築することができない可能性が高いです。そうしたケースでは、こうした時間発展に常微分方程式(状態空間モデル?)を使うようなアプローチは特に有効なのかもしれないと思いました。
上の SIRモデルでは、常微分方程式の係数は定数となっていますが、Google のモデルでは、これらの定数をさまざまな共変量から予測するような仕組みになっています。
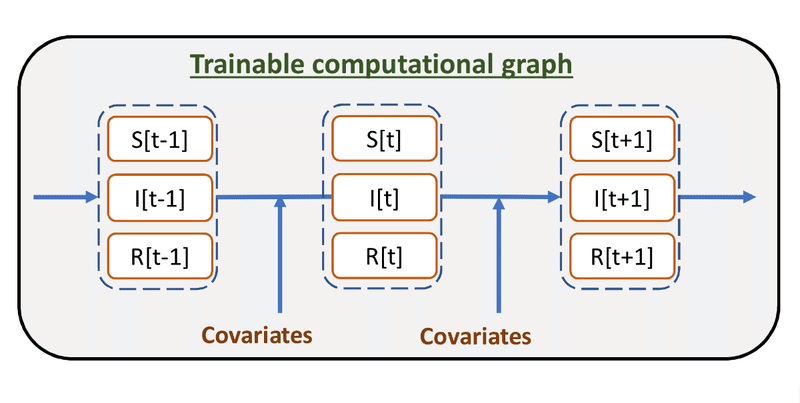
つまり、基本的な時間発展は SIR のような常微分方程式で制御される一方で、その微分方程式系の係数部分を観測可能な共変量で予測するような仕組みになっています。
例えば、政策等の何らかのファクターで人々の接触が減らされたような場合に係数βを小さくするというようなモデルが組み込まれていれば、そうしたファクターも比較的容易にモデルに取り込むことができるという訳です。
係数の予測
Google のモデルでは、基本的には常微分方程式の係数(βなど)を次のような一般化加法モデルで推定しています。
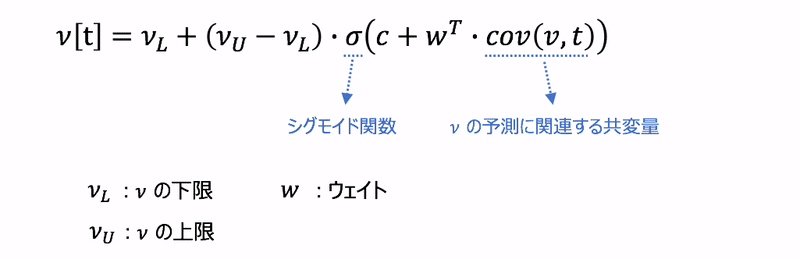
こうしたモデルは、地域ごとに微妙に異なる可能性があるので、こうした違いを吸収させるために実際のモデルでは更に地域を表す添字 i を導入して、次のようにモデルを拡張しているようです。
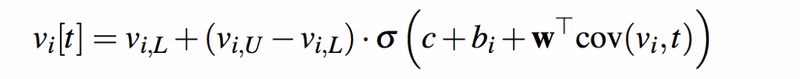
上のモデルの bi が、地域ごとの違いを「ランダム効果」として表現している部分になります。ただ、こうしたパラメータも完全に自由に動かしてしまうと、地域ごとの違いをこの定数が吸収しすぎてしまう可能性があるので、パラメータ推定の際にはこれらのパラメータが自由に動けないように、次のような正則化項で縛りをかけます。
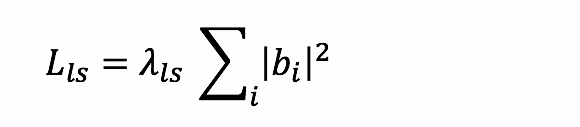
ちなみに、ホワイトペーパーでは bi は、「ランダム効果」ではなく、"Local Bias" と呼ばれていました。また、このモデルには地域間の影響などもモデルに組み込めるっぽいのですが、詳細は読みきれませんでした。

興味のある方は、直接ホワイトペーパーを読んで頂けたらと思います。
感染モデルの拡張
ここまで SIR モデルをベースに解説をしてきましたが、実際のモデルはもうちょっと複雑なようで、ホワイトペーパーには、以下のような図がありました。
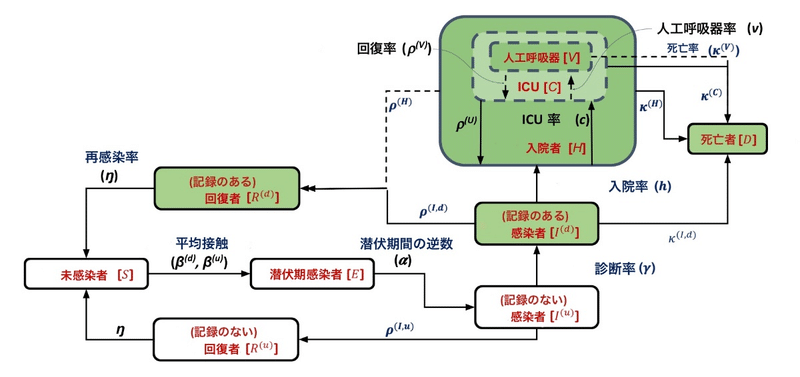
元々のダイアグラムは英語だったのですが、日本語の方が見やすいので、和訳してみました(素人の翻訳なので、あまり信用しないで下さい!)。ちなみに、ダイアグラムの中で使われている変数や係数などは次のようになっています。
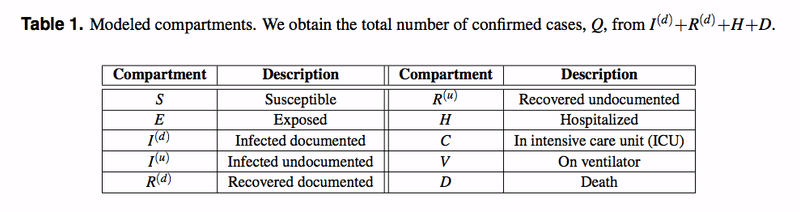
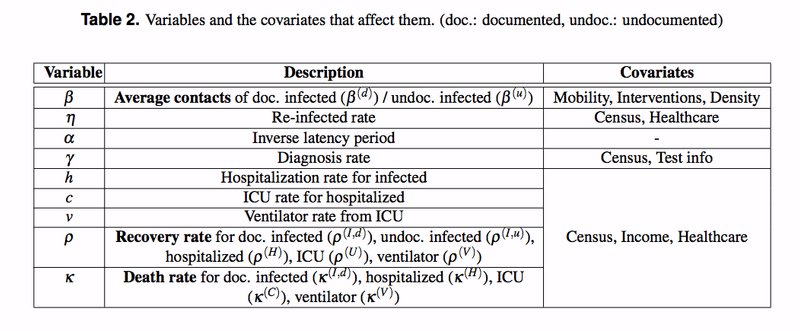
このダイアグラムを見ると、結構わかりやすいのですが、実際の微分方程式は次のようになっており、なかなかに強烈です。
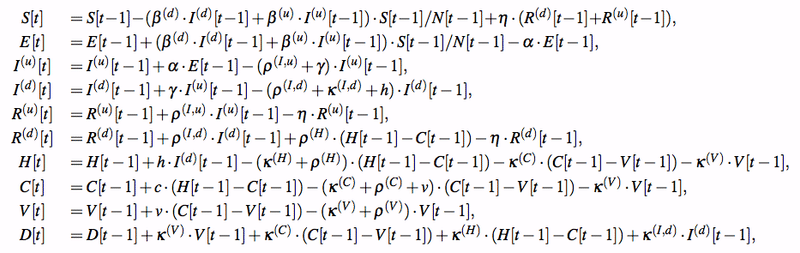
ただ、実際には丁寧にダイアグラムを辿っていけば、上の式は導出できそうなので、技術的に難易度が高い、というよりは手数がかかるだけと思われます。反面、モデルの解釈性は高く、モデルの妥当性や正当性の検証(sanity check)などは非常にやり易そうな気がします。
特に、ダイアグラムと連動した可視化の仕組みがあれば、メンテナンス等の観点からも非常に優れたモデリングができそうな気がします(Google の社内では既にそういうシステムがあるのかも…)。
パラメータ推定の方法
パラメータ推定の方法は、基本的にはモデルに予測させたときの予測値と真値との差分を L2-norm 等で評価して、RMSProp でパラメータ推定します。

但し、データには欠損があるため、尤度関数はそれほど単純ではないようで、未観測のデータについては指示関数(indicator function)等を使って、尤度関数から丁寧に外してやる必要があるようです。
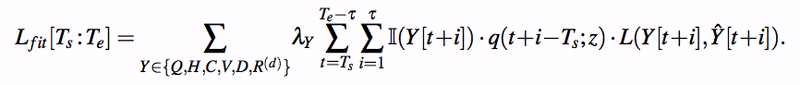
また、正則化についても、先に紹介した正則化項以外にも正則化項を導入している模様で、かなりさまざまな手法を駆使している印象があります。詳細については、Google のホワイトペーパーを直接見て頂けたらと思います。
感想
データ解析の現場では、普段いろいろと難しい問題に遭遇することがあるかと思うのですが、私が最近個人的に特に難しいと感じたケースは、次のようなものです。
■ ビッグデータとスモールデータの混在するデータでのモデル化と予測
■ 定常性が必ずしも保証されない時系列のデータでの未来予測
■ モデルの解釈性を担保する必要がある対象のモデル化
そして、今回取り上げた COVID-19 のモデル化に関しては、これら全ての条件が当てはまる、という意味でまさに最難関とも言えるモデリングかもしれないと思いました。
データが大量にあり、なおかつ共変量シフトが発生しないような問題については、現在はフレームワークをうまく活用して、それなりの結果を出すことができるようになってきていますが、今後はそれ以外の問題をどう解くか? という問題にもフォーカスが当たるのではないかと思っています。
つまり、データが普段とは違う動きをしたときにアルゴリズムがどう動くか? あるいは、学習データと性質や傾向の異なるデータが入力されたときにも突拍子もない動きをしないかどうか? といったことも、これからのモデリングでは重要になってくるように思っています。
特に、時系列データを使った未来予測では、一般的には定常性が崩れないことが大前提になっているケースが多いかと思うのですが、今回の COVID-19 のモデルでは、定常性はないことが大前提になっており、時系列データのモデリングとして学ぶべき点が多いモデルであると思いました。
補足
一般的な時系列のモデリングなどでは、Prophet なども使われることも多いのですが、Prophet のモデルの持つトレンドは基本的には線形のトレンドで、未来予測に関しては基本的には単調なトレンドしか予測できません。つまり、単調に下がり続けるトレンドか、単調に上がり続けるトレンドしか予測できません。
上限や下限を設定したりすることもできるので、予測値が無限伸びてしまうようなことは回避できますが、今回のコロナのように一定時間経過後にゆっくりと元に戻る、といった時間発展をモデル化する仕組みはないと思われます。
もちろん、これも手動でモデル化を行えば、そうしたモデルを作ることはできるのですが、一般的にこうしたモデルはいまのところ手作りするしかなく、モデル化をする際にも手間がかかるので、今回コロナのモデルが比較的短期間が出てきたのも長年の研究者の蓄積があればこそ、と思いました。